



The problem
The Internet was born as an open, decentralized and scalable infrastructure supporting the visionary dream of an interconnected world of data, information and services. Never like in the last decade we have witnessed a booming expansion of the Internet in terms of infrastructure (e.g., available bandwidth), services (e.g., online social networks, online streaming but also online banking, health care, to mention some), and user generated content. The Internet is considered a means for ensuring human rights, such as freedom of speech and expression, and a structural way for educating people on democracy [4]. While the debate is raging whether the Internet should be called a “utility” by virtue of being a fundamental human right, the Internet runs the risk of becoming our biggest liability.
While the benefits of an interconnected society are immediately clear to everybody, it has recently became more and more evident even to laypeople that the Internet exposes us to cyberthreats attacking information, services and even the Internet infrastructure itself (e.g. attacks against the Domain Name System). Chief examples are (Distributed) Denial of Services attacks (DDoS), an old threat that has recently taken new shapes and proportions (e.g. the attacks against the hosting company OVH (2016, 1Tbps) [13], or the attack against the service and DNS provider Dyn [7]); but also ever more advanced phishing attacks (e.g. CEO fraud [11]), advanced spam campaigns (e.g., snowshoe spam) and other forms of insidious activities.
When a cyberthreat makes its appearance on the Internet, a mitigation strategy follows right after. The rise of DDoS attacks, for example, has paved the way to a new market for DDoS protection systems, i.e. appliances and services aiming at stopping malicious traffic from hindering a certain service [9]. In the Netherlands, a notable initiative in this respect is NaWas¹ (de nationale anti-DDoS Wasstraat), performing data cleansing. Research in the field of detection and mitigation has already indicated that the Domain Name System (DNS) plays a central role as source of data for security. This is because most Internet services and applications (not necessarily benign) strongly rely on the DNS for their functioning (e.g. mail, web, DDoS protection services, but also botnets and spam, to name some). The work in [3, 2], for example, analyzes user-generated DNS traffic to identify botnet command-and-control traffic. In practice, there exists a plethora of mechanisms to protect us from cyberthreats (e.g., firewalls, blacklists, ACL, IDS, DDoS protection services etc.). What all these solutions have in common, however, is that they are reactive. In other words: they only come into play when an attack is already ongoing.
Novelty
The novelty of this research is that we propose a focus shift from reactive security to proactive security: we advocate a security approach that aims at preventing an attack from taking place by identifying threats in the making. We propose to do this by means of an active DNS measurement, spanning 60% of the overall name space over a duration of two years, and growing.
The rationale for this research is that sophisticated attacks are not anymore a matter of running a script, but they require careful preparation. For example, attack phases need to be staged and additional infrastructure needs to set up. In preparing an attack, however, attackers might expose characteristics of their infrastructure that can be used to predict an attack. Our intuition, backed by the preliminary analysis presented in Sec. 4, tell us that DNS data will contain evidence of such preparatory activities, since also attackers, like anyone else nowadays, have to rely on the DNS system as support for their activities. In the case of DDoS attacks, for instance, crafted domain names that will enlarge the volume of an attack need to be registered and updated in the DNS to be later misused. In the window between crafting such a domain and performing an attack, a fundamental piece of the attack infrastructure is exposed and vulnerable, providing us with a chance to actually prevent attacks from happening.
Goal of the project
The goal of this project is the proactive identification of threats, before the actual attack has taken place. To achieve this, we will focus on DNS data, as the DNS is one of the core infrastructures of the Internet and the basis of the functioning of most services nowadays. Our research will focus on the following three objectives. First, we aim at identifying threats characteristics in DNS data. Secondly, we aim at validating our findings on a set of real-world threats examples, such as, among others, spam, DDoS attacks and phishing. Last, we aim at making threat information accessible to security experts and operators, for example by creating threat blacklists.
The approach taken will be measurement-based. For this, we will make use of the data collected in the OpenINTEL platform² [18], which performs a long-term (longitudinal) active measurement of the global Domain Name System (DNS) to track trends and developments on the Internet.
Approach and Methodology
A measurement approach The Domain Name System (DNS) is a core component of the Internet. It performs the vital task of mapping human readable names into machine-readable data (such as IP addresses, which hosts handle e-mail, etc.). The content of the DNS reveals the technical operations of a domain. Thus, studying the state of large parts of the DNS over time reveals valuable information about the evolution of the Internet. Most research conducted using DNS data focuses on one-shot measurements based on passive DNS activity (e.g., [12]). We follow a completely different approach.
Since February 2015, we collect a long-term dataset with daily DNS measurements for all domains under the main top-level domains on the Internet (including .com , .net and .org, and several ccTLDs, among which .nl). The dataset is world-wide unique both in duration (soon reaching 2 years of uninterrupted collection), as well as in extension, since it comprises more than 60% of the global DNS name space (almost 200M domain names).
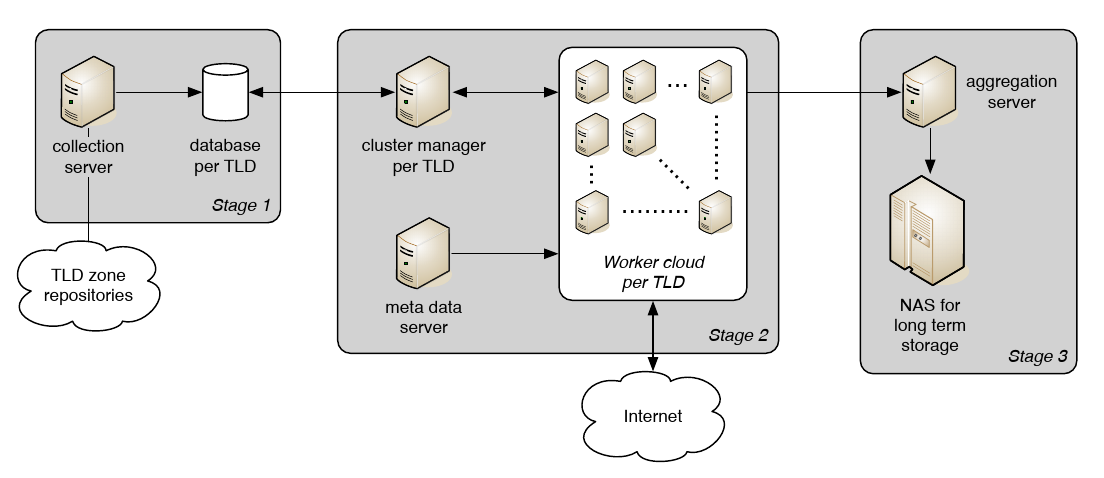
The advantage of a structured, long-term, active measurement is that it allows us to track the evolution of the Internet, such as adoption of new protocols and services [18, 17] and security measures [9], without possible biases introduced by user behavior (as in passive studies). Fig. 1 shows an overview of the measurement architecture. The overall measurement is structured in three stages. In the first stage (Fig. 1-left), we collect the input data, namely by downloading the zone files and consolidating them in a database that keeps track of the lifetime of a domain. In the second stage (Fig. 1-center), a cluster of workers queries the DNS for resource records related to domains in the considered zones. At this stage, the collected data are enriched with metadata such as Autonomous System Numbers and geolocation information. Finally, the last stage (Fig. 1-right) takes care of storing the data and preparing them for analysis by inputting them in a Hadoop cluster. The measurement delivers more than 2.2 billion data points daily.
Characterizing threats
When dealing with a number of datapoints in the order of several billion (and growing), it is of the utmost importance that the data analysis, which is a prerequisite for the threat characterization, is feasible. In other words, we need to ask ourselves “Where and how can I find what I am looking for?”. Our approach for characterizing threats is therefore based on two cornerstones:
-
Domain-specific knowledge – Our previous experiences with the DNS data we collect (e.g., [18, 17, 9]) have taught us that domain-specific knowledge of the phenomenon one intends to investigate is fundamental for reducing the amount of data to be analyzed and extract only the relevant information. Examples of domain-specific knowledge in the context of DNS data are, among others, the notion that attackers misuse domains that give large DNS responses for DDoS attacks; or the fact that DDoS protection services (e.g. Cloudflare) are implementing their services using DNS-based traffic redirection, which is visible in our data [9].
-
Automatic pattern extraction – Filtering the data based on domain-specific knowledge is an important first step for analyzing our dataset. However, it might not be sufficient. In same cases, a characterization of a specific threat cannot be done based only on domain-specific knowledge, but it needs instead to be done based on patterns in the data. We therefore propose to use machine learning (e.g. clustering) methods for automatically extract similarity patterns from the data.
Validation and application
Finally, our findings with respect to the characterization of threats need to be validated. We plan to do this on a set of real-world scenarios, such as, among others, spam, DDoS attacks and phishing. For the validation, we will rely on additional data sources such as blacklists (e.g., SBL, CCS and PhishTank), DDoS attack data (e.g., from the AmpPot project [10] form Saarland University). The validation will tell us not only if we have found an appropriate characterization for a particular threat, but also with how much confidence we can expect that a threat will evolve into an attack in the future. We plan to make available such high-confidence, validated results to security experts and operators by means of dedicated threats blacklists.
Multidisciplinary aspects
Applying a proactive methodology to identify threats before they happen is not risk-free. Acting on possible threats, even when the confidence is high, might cause hindrance to unaware users (e.g., by dropping requests when we should have not), or undeservedly point the finger to innocent parties (e.g., when a prediction is not correct). To avoid proactive identification to be conceived as crying wolf, it is important to ensure that the measurements and analysis are carried on in an ethical manner. Ethics in network security is more than a discipline: it is a way of thinking. To ensure that the Ph.D. candidate working on the project will have the appropriate mindset and critical thinking tools for addressing ethical aspects, the candidate will work in close collaboration with the Ethical Committee and the Department of Philosophy of the University of Twente (Dr. A. van Wynsberghe, Dr. J. Soraker). We have an excellent track record in ethical security research, illustrated for example by one of our current Ph.D. students co-authoring an ethical reflection on his work with our Department of Philosophy [5].
Relevance
Scientific relevance
The research we propose is based on a world-wide unique dataset. As such, this dataset enables research that was scientifically not possible before the data were collected at this scale and in this timeframe. At the time of writing, the dataset covers 60% of the domain space and consists of daily measurements for a duration that is now approaching two years and will continue for the foreseeable future. In addition, we are working such as to extend the measurement with new ccTLD. Our research so far [18, 17, 9] has already proven the relevance of the data we collect. The research we propose here builds upon the collected dataset and our previous publications, thus leveraging on scientific knowledge and relevant security problems for both the academic as well as operational community. This proposal, in the specific, tackles one of the core issue with security today, namely the often-heard problems that “we are always one step behind” the attackers. By proposing a proactive approach to threat identification, we aim at addressing security threats before an attack takes place. Similarly to us, the work in [1] advocates the existence of a “germination period”, i.e. the period between the hacker community starts discussing a new vulnerability to the moment this is exploited. However, [1] suggests that early evidence could be found by mining hacker discussion forums and blogs. Compared to our DNS-based approach, such a solution would have to deal with the unpredictability of human-created content, while we instead have the advantage of relying on a structured measurement and validated data. In this respect, our research is complementary to other DNS-based measurement efforts. For example, SIDNLabs has developed the ENTRADA system [20, 21], a network traffic data streaming warehouse which is operationally used for fast analysis of DNS data with the goal of improving the security and stability of the .nl zone. While ENTRADA focuses mostly on DNS traffic, our research focuses instead on the data in the DNS. The two measurements provide therefore complementary views of how the DSN is (mis)used in practice [6].
Societal relevance
Our goal is to proactively identify threats before the actual attack take place. Cyberattacks strikes in every aspect of nowadays society. Reports such as the “2016 Cost of Cyber Crime Study & the Risk of Business Innovation” [8] by the Ponemon Institute indicates that the cost of cybercrime for companies ranges in the 4-18 Million USD per company for year 2016, with a clear increasing trend over the last four years. While it is easier to point to a loss of revenue for companies hit by cybercrime, cyberattacks are nowadays a phenomenon involving, as attacked or perpetrator, large portion of society. Previous research at the DACS group [16, 15] has shown how easy it is, even for the layman, to launch his own DDoS attack using Booters (DDoS-as-a-Service, which unfortunately seems to be quite common also among students to avoid exam periods). This research has the potential of stopping attacks from happening. In practice this would mean that the overall cost of cyberattacks and the number of related disruptions will decrease, therefore directly limiting the societal damages caused by cyberattacks.
Case studies and expected results
The research we propose takes a proactive approach to the identification of malicious domains in the DNS. The standpoint from which this research stems is that, while the vast majority of DNS uses is benign, the DNS can also serve as an intermediary in malign behavior (e.g., in spam campaigns or in botnet command and control) or be an attack vector (e.g., in amplification attacks). Since a domain needs to be operational if it is to play a role in malicious behavior, actively monitoring the data in the DNS can reveal domains crafted for malicious activities before these occur.
Preliminary analyses of the collected DNS data to identify malicious domains have shown promising results. In the following, we will present highlights for two possible case studies, snowshoe spam and Amplification DDoS attacks, and then describe the results we expect from this research.
Case study 1 – Snowshoe spam
The impact of spam (unsolicited e-mail) on users ranges from a nuisance to a major threat if it is used to spread malware or misdirect users to enter sensitive information in fake websites (phishing). Spam has been around for a long time, and enhancing spam filters with blacklists of known spam sources has proven to be an effective countermeasure. Clearly, spammers want to avoid appearing on blacklists to increase their success rate. This has led to the appearance of snowshoe spam (a term first coined in 2009)3 . In this approach the sending of spam is spread across a multitude of IP addresses and domains, with each sending only a small fraction of the spam batch. It is much harder for anti-abuse operations to detect and blacklist IPs and domains associated with this behavior, which has led to the creation of specific blacklists for this type of spam3 . Yet while anti-abuse organisations invest significant effort to tackle the problem of snowshoe spam, it remains a challenge to effectively identify this type of spammers [14].
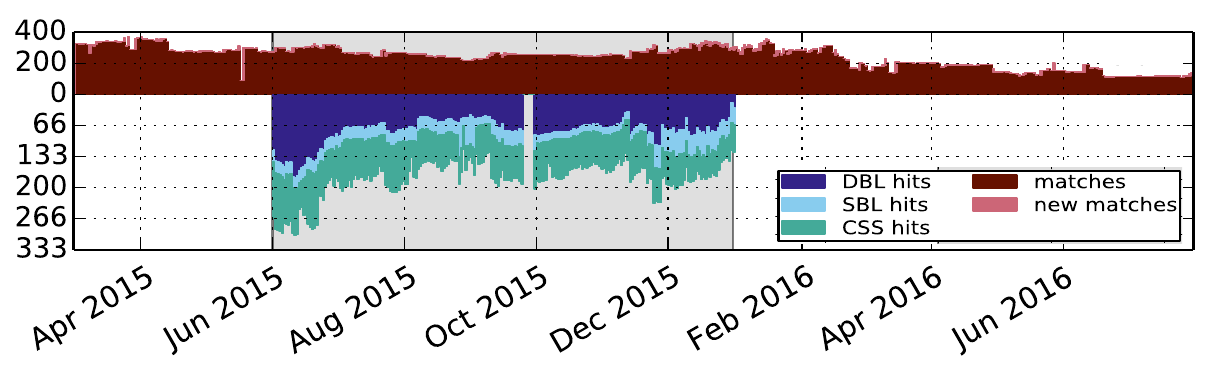
The Achilles heel of snowshoe spam, however, is that it needs careful preparation to be effective. We therefore expect domains crafted for sending snowshoe spam to stand out in DNS data, for instance because they contain excessive numbers of address (A) records pointing to the IP addresses over which the load of sending spam is distributed. In Fig.2 we show precisely this case. The area above the zero-line indicates the number of domain per day that meet a specific threshold on the number of A records. This proves that such type of suspicious domains is visible in the data we collect. In addition, we verified if the domains we identify appear also in known spam blacklists (e.g. DBL, SBL and CCS). The result is visible in Fig.2 for the timeframe June 2015 to January 2016. The area below the zero-line indicates that the domains we identify in the DNS data do appear at a certain moment in time in one of the considered blacklists. Moreover, further analysis shows that we can proactively identify 58.5% of the possibly spam-crafted domains more than 25 days before they appear in the blacklist.
This case study shows how snowshoe domains can be characterized by looking at an unusually high number of A records. The validation using spam blacklists proves that proactive identification is possible with high confidence.
Case study 2 – Crafted domains for Amplification DDoS attacks
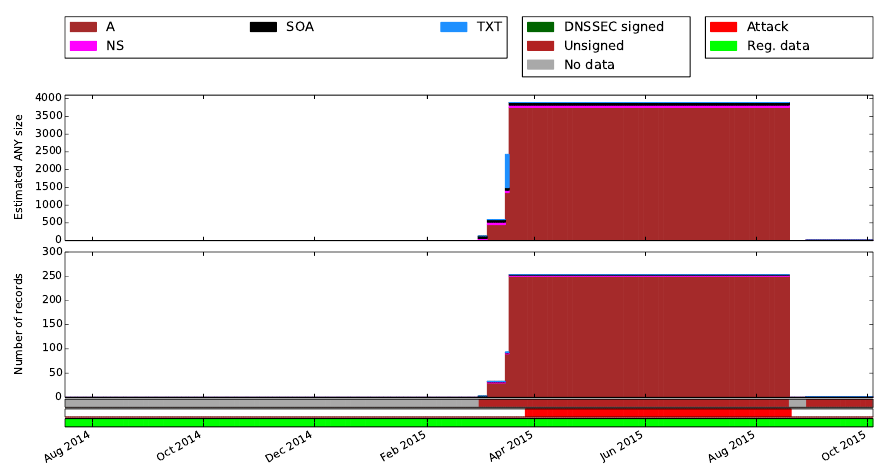
DNS amplification is a form of distributed denial-of-service (DDoS) attack in which an attacker will prompt the DNS to answer fake queries seemingly generated by the target. The attacker will typically send a query for which he knows the response will be very large, to maximize the amplification effect. The attacker can do this in two ways. The first option is to craft a domain that he controls, populated with one or more records that guarantee a large response. The second option is to use an existing domain for which the attacker knows the answer to certain queries to be large, for example a domain that is DNSSEC-signed [19]. In this proposal, we focus on attackers that choose the first option. We expect domains crafted for DDoS to stand out because an attacker has an incentive to maximize the response size for a domain to achieve high amplification. Fig. 3 shows an example of a domain, sunrisecx.com that shows a behavior compatible with the one described above. In particular, Fig. 3 shows that, while the domain was registered well in advance (bottom green bar), the number of records and the estimated amplification size (as carried, for example, in an query of type ANY) was modest until March 2015. Starting from March 2015, we observe that the domain has been inflated, specifically by adding more than 200 A records, reaching an estimated ANY size of 3500 bytes. This coincides with the time windows in which the domain is used in DDoS attack (bright red bar, based on data from the AmpPot project [10]). After the attack window ends, in September 2015, the domain deflates.
This case study shows that domains crafted to be used in Amplification DDoS attacks can be characterized by the estimated amplification size. The validation based on the window of time a domain is used for attacks shows that, also in this case, we can achieve high confidence in the proactive identification of attacks.
Expected results
The case studies we presented clearly prove that we can proactively identify threats before the actual attack takes place. The case studies also prove that the active DNS measurements we collect in the context of the OpenINTEL platform are able to support the proposed research, providing both a snapshot of the current situation (daily measurements) as well as an historical (longitudinal) view of a security phenomenon (2-year measurement). From this research, we therefore expect the following results:
-
A DNS-based characterization of threats – The DNS data we collect are a rich dataset with 10-14 resource records, for the apex of the domain and for the “www.” label, associated to each domain we query. The case studies we have highlighted have so far considered only A records or the expected size of ANY records. In the context of this research, we plan to systematically re-evaluate the collected data with the goal of identifying and characterizing threats. To ensure that the threats we focus on are relevant and timely, we will leverage on our network of knowledge and work in close collaboration with e.g., SURFnet and SIDNLabs. Such characterization will allow us to quantify the potential of the research we propose, and to focus on cutting edge threats for our society.
-
Validation – Proactively identifying threats does not provide certainty that an host or domain has participated in attacks (like it is the case, for example, in well-known defense mechanisms such as spam blacklist). However, it will tell you that an attack might happen in the near future, since there is evidence that the attack is in preparation. When working with proactive identification, it is important to quantify the confidence we have in the possibility that threats will turn into actual attack. One of the expected outcomes of this project is therefore a validation of our proposed approach in the case of real-world scenarios.
-
Threat blacklists – Last, we expect this research to lead to a dedicated approach to use the identified threats to prevent attacks, thus fulfilling the proactive and actionable nature of the proposed research and enhancing its the operational impact. This research will therefore lead to the creation of threats blacklists, listing domains and/or IP addresses that we expect might be part of future attack.
References:
- H.-M. Chen, R. Kazman, I. Monarch, and P.Wang. Can Cybersecurity Be Proactive? A Big Data Approach and Challenges. In Proceedings of the 50th Hawaii International Conference on System Sciences (HICSS 2017), 2017.
- Hyunsang Choi and Heejo Lee. Identifying botnets by capturing group activities in DNS traffic. Computer Networks, 56(1):20–33, 2012.
- Hyunsang Choi, Heejo Lee, and Hyogon Kim. BotGAD: detecting botnets by capturing group activities in network traffic. In Proc. of the 4th Int. ICST Conf. on Communication System softwAre and middleware (COMSWARE 2009), 2009.
- H. Clinton. Remarks on Internet Freedom. https://www.state.gov/secretary/20092013clinton/rm/2010/01/135519.htm, January 2010.
- David Douglas, José Jair Santanna, Ricardo de O. Schmidt, Lisandro Zambenedetti Granville, and Aiko Pras. Booters: Can Anything Justify Distributed Denial-of-Service (DDoS) Attacks for Hire? To appear in Journal of Information, Communication & Ethics in Society (JICES), 2016.
- Giovane C. M. Moura, Moritz Muller, Marco Davids, Maarten Wullink, and Cristian Hesselman. Domain names abuse and TLDs: from monetization towards mitigation. In 3rd IEEE/IFIP Workshop on Security for Emerging Distributed Network Technologies (DISSECT 2017), co-located with IFIP/IEEE International Symposium on Integrated Network Management (IM 2017), May 2017.
- Scott Hilton. Dyn Analysis Summary Of Friday October 21 Attack. http://dyn.com/blog/dyn-analysis-summary-of-friday-october-21-attack/, Oct. 2016.
- Ponemon Institute. 2016 Cost of Cyber Crime Study & the Risk of Business Innovation. http://www.ponemon.org/local/upload/file/2016%20HPE%20CCC%20GLOBAL%20REPORT%20FINAL%203.pdf, 2017.
- M. Jonker, R. van Rijswijk, R. Sadre, A. Sperotto, and A. Pras. Measuring the Adoption of DDoS Protection Services. In ACM Internet Measurement Conference 2016 (IMC 2016), 2016.
- Lukas Krämer, Johannes Krupp, Daisuke Makita, Tomomi Nishizoe, Takashi Koide, Katsunari Yoshioka, and Christian Rossow. AmpPot: Monitoring and Defending Amplification DDoS Attacks. In Proceedings of the 18th International Symposium on Research in Attacks, Intrusions and Defenses, November 2015.
- Brian Krebs. FBI: $2.3 Billion Lost to CEO Email Scams. https://krebsonsecurity.com/2016/04/fbi-2-3-billion-lost-to-ceo-email-scams/, Apr. 2016.
- C. Lever, R. Walls, Y. Nadji, D. Dagon, P. McDaniel, and M. Antonakakis. Domain-z: 28 registrations later measuring the exploitation of residual trust in domains. In 2016 IEEE Symposium on Security and Privacy (SP), May 2016.
- Pierluigi Paganini. The hosting provider OVH continues to face massive DDoS attacks launched by a botnet composed at least of 150000 IoT devices. http://securityaffairs.co/wordpress/51726/cyber-crime/ovh-hit-botnet-iot.html, Sept. 2016.
- Jordan Robertson. E-mail Spam Goes Artisanal (Bloomberg Technology). http://www.bloomberg.com/news/articles/2016-01-19/e-mail-spam-goes-artisanal, 2016.
- José Jair Santanna, Ricardo de O. Schmidt, Daphne Tuncer, Joey de Vries, Lisandro Granville, and Aiko Pras. Booter blacklist: Unveiling ddos-for-hire websites. In International Conference on Network and Service Management (CNSM)., 2016.
- José Jair Santanna, Roland van Rijswijk-Deij, Anna Sperotto, Rick Hofstede, Mark Wierbosch, Lisandro Zambenedetti Granville, and Aiko Pras. Booters – an analysis of ddos-as-a-service attacks. In IFIP/IEEE International Symposium on Integrated Network Management (IM), 2015.
- R. van Rijswijk, M. Jonker, and A. Sperotto. On the Adoption of the Elliptic Curve Digital Signature Algorithm (ECDSA) in DNSSEC. In 12th International Conference on Network and Service Management (CNSM 2016), 2016.
- Roland van Rijswijk-Deij, Mattijs Jonker, Anna Sperotto, and Aiko Pras. A High-Performance, Scalable Infrastructure for Large-Scale Active DNS Measurements. IEEE Journal on Selected Areas in Communications, 34(7), 2016.
- Roland van Rijswijk-Deij, Anna Sperotto, and Aiko Pras. DNSSEC and its potential for DDoS attacks. In Proc. of the 2014 Conf. on Internet Measurement Conference (IMC 2014), 2014.
- M. Wullink, G. C. M. Moura, M. Muller, and C. Hesselman. ENTRADA: A high-performance network traffic data streaming warehouse. In NOMS 2016 – 2016 IEEE/IFIP Network Operations and Management Symposium, pages 913–918, April 2016.
- M. Wullink, M. Muller, M. Davids, G. C. M. Moura, and C. Hesselman. ENTRADA: enabling DNS big data applications. In 2016 APWG Symposium on Electronic Crime Research (eCrime), June 2016.
